Quilla (Knowledge Extraction based on Evolutionary Learning) és una eina de programari basada en Java especialitzada en la implementació d'algorismes evolutius. Com que és un codi obert, proporciona una àmplia varietat d'algoritmes de descobriment de coneixement que es poden utilitzar en experiments que impulsen la comunitat d'anàlisi i mineria de dades. Proporciona una interfície d'usuari gràfica senzilla i fàcil d'utilitzar que redueix significativament la complexitat general d'aquesta eina. La majoria d'eines similars del mercat requereixen que els usuaris interactuïn amb elles escrivint el codi, mentre que Keel elimina aquest requisit proporcionant una GUI intuïtiva que pot utilitzar tant per principiants com per experts.
Keel ofereix una gran varietat d'algoritmes basats en intel·ligència computacional, com ara classificació, regressió, extracció de característiques, anàlisi de patrons, agrupació i molt més. Amb els models principals incorporats directament a l'aplicació, Keel és una eina molt útil quan es tracta de realitzar anàlisis exploratòries de dades en conjunts de dades en brut. La seva senzilla interfície d'arrossegar i deixar anar combinada amb la facilitat d'utilització de la funcionalitat permet una experimentació ràpida i eficient de la mineria de dades amb finalitats educatives i de recerca. Eines com Keel estan augmentant en popularitat a causa del seu enfocament simplista de pràctiques algorítmiques d'altra manera complexes.
Instal·lació
Hi ha dues maneres principals en què podem instal·lar Quilla en qualsevol màquina Linux. La primera consisteix en anar al Pàgina web de Keel i baixant el programari des d'allà. El segon, que seguirem en aquesta guia d'instal·lació, ens obliga a descarregar Keel mitjançant el wget eina de descàrrega disponible per als usuaris de Linux.
1. Comencem per aconseguir wget a la nostra màquina Linux.
Executeu l'ordre següent per descarregar el wget utilitzant el apt gestor de paquets:
$ sudo apt-get install wget
Veureu una sortida de terminal similar:
2. Ara que tenim el wget instal·lada a la nostra màquina Linux, la fem servir per descarregar el fitxer Quilla eina.
Aquest és el enllaç que passem a wget.
Executeu l'ordre següent al vostre terminal:
$ wget http: // sci2s.ugr.es / quilla / programari / prototips / openVersion / programari- 2018 -04-09.zip
Hauríeu de veure una sortida similar al vostre terminal:
Un cop finalitzada la descàrrega de Keel, podem continuar amb la resta de la instal·lació.
3. Ara extreim el fitxer comprimit que vam descarregar al pas anterior mitjançant l'eina Linux Unzip.
Executeu l'ordre següent:
$ descomprimir programari- 2018 -04-09.zip
Hauríeu de veure una sortida similar al terminal:
4. Navegueu a la carpeta Keel executant l'ordre següent:
$ cd programari- 2018 -04-09 / Documents / Experiments / QUILA / dist /
5. Executeu l'ordre següent per començar amb la instal·lació:
$ java -gerro . / GraphInterKeel.jar
Amb això, Keel hauria d'estar disponible per utilitzar-lo a la vostra màquina Linux.
Guia de l'usuari
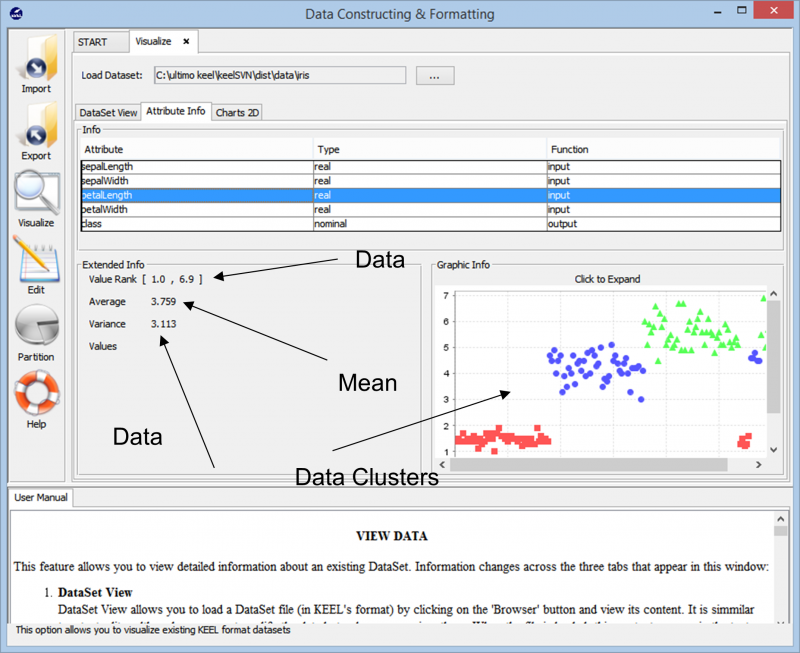
Interaccionant amb el Quilla l'aplicació és realment fàcil i senzilla. Comencem per importar el Conjunt de dades de l'iris al nostre espai de treball.
A mesura que importem les dades, l'eina ens mostra l'agrupació general del punt de dades al conjunt de dades. També ens mostra les diferents classes que hi ha al conjunt de dades juntament amb la informació bàsica com els intervals numèrics que abasten aquests punts de dades i la variància global i els valors mitjans que presenten. Aquesta informació permet als usuaris entendre millor com procedir amb la preparació de dades per a qualsevol tipus de tasca d'anàlisi de dades.
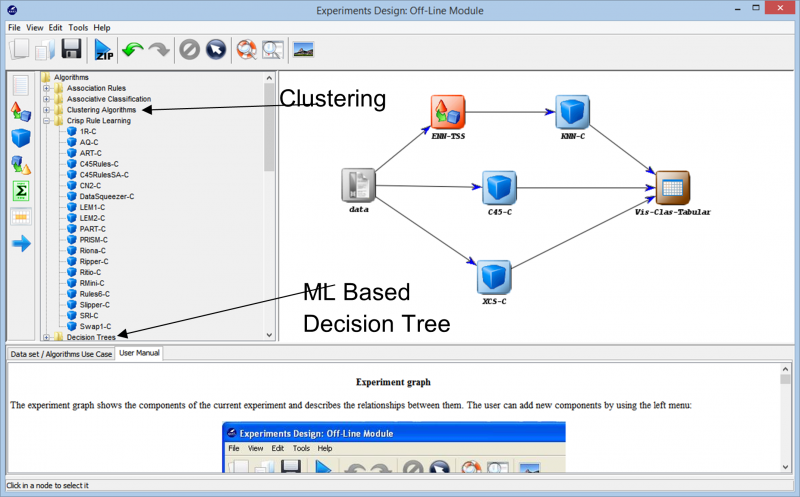
Avançant més endavant en l'experimentació, ens trobem amb les diferents tècniques que es poden utilitzar per crear el nostre experiment amb qualsevol conjunt de dades. Els diferents algorismes d'aprenentatge que es poden utilitzar amb les nostres dades es poden veure a la següent imatge. Depenent de la naturalesa del conjunt de dades i dels requisits de l'experiment, es poden experimentar amb diferents algorismes.
Per exemple, si treballeu amb dades sense etiquetar i heu de trobar similituds entre els diferents punts de dades del vostre conjunt de dades, l'ús d'un algorisme de agrupació de les diferents opcions disponibles us pot ajudar a comprendre millor els punts de dades. Finalment, això us ajudarà a etiquetar i classificar els punts de dades perquè l'experiment es pugui basar en algorismes d'aprenentatge supervisat més complets.
Conclusió
El Quilla La plataforma per a l'anàlisi de dades és un bon recurs tant per a finalitats d'investigació com per a finalitats educatives. La seva interfície gràfica d'usuari fàcil d'utilitzar ajuda els usuaris a entendre millor els requisits de les dades, a més de proporcionar referències lògiques a tècniques i algorismes útils que ajuden encara més els usuaris en els seus fluxos de treball. Disposar d'una àmplia gamma d'algorismes diferents que s'inclouen en les diferents categories i tècniques algorítmiques permeten als usuaris experimentar amb nombroses direccions lògiques i comparar aquests resultats de manera que es pugui arribar a la solució més òptima a qualsevol problema.
L'enfocament d'arrossegar i deixar anar sense codi de Keel per a la mineria de dades ajuda fins i tot als principiants a treballar sense esforç amb models d'intel·ligència computacional integrals. Això proporciona informació sobre conjunts de dades complexos i, per tant, deriva inferències útils que ajuden a resoldre els problemes del món real.